Proving 50-Year-Old Sorting Networks Optimal: Part 1
Last December, I finished writing a paper where I prove optimality of the 11 and 12-channel sorting networks found by Shapiro and Green in 1969 which are presented in D. E. Knuth’s “The Art of Computer Programming” vol. 3 [9]. While they have been conjectured to be optimal for a long time, proving this has been an open problem.
In this first post I will introduce the problem and give some context. In future posts I will describe my result and how I got there. If you’re interested in all the proofs and technical details you can read the paper and look at the accompanying source code and formal proofs right now.
Sorting networks
Sorting a list must be one of the most studied problems in computer science. Most of the time this is done with comparison sorts which are algorithms that inspect the items only by comparing two of them at a time to obtain their relative order. This is a very general approach, as it does not make use of the items representation or any specific properties besides having a linear order. Quicksort, merge sort and heap sort belong to this class, while approaches like radix sort or counting sort do not.
In all of these comparison sorts though, the information which of the compared items was smaller influences the steps performed afterwards. In some way, of course, that information has to be used, but we can limit this to the absolute minimum. We do this by only using compare-exchange operations. A compare-exchange is a comparison of two items immediately followed by optionally swapping them such that they are in a known order afterwards. Alternatively you can view it as replacing a pair of values with their minimum and maximum in a specified order. A sorting algorithm that only uses compare-exchange operations without looking at which of the items was smaller is called a data-oblivious (comparison) sorting algorithm.
If we further drop the requirement of sorting lists of any size, but instead fix the input length, we obtain something called a sorting network. A sorting network is fully specified by the list of compare-exchange operations it performs. In the context of sorting networks, the positions of a list of length are called channels and a compare-exchange operation is also called a comparator. To specify a comparator we write a pair of channels in square brackets (e.g. ) where the first channel receives the smaller value and the second channel the larger value. To specify a sorting network, we then write the performed operations from left to right (e.g. ).
We can also draw a sorting network as a diagram like this:
![Diagram for the sorting network [1,3][1,2][2,3]](diagram-standard.svg)
Here the horizontal lines correspond to the channels. Each comparator, from left to right, is drawn as a vertical line, starting at the comparator’s first channel and ending at the comparator’s second channel. Now this is ambiguous because comparators are not symmetric—one channel receives the smaller value and the other the larger—so by convention the upper channel receives the smaller value. If we want to have comparators oriented the other way, we draw them as arrows pointing to the channel receiving the larger value. Additionally we can also reorder channels using unconditional exchanges, written using round brackets, like this:
![Diagram for the sorting network 3,11,3[2,3]](diagram-directed.svg)
It turns out that we only need the default comparator orientation and need no unconditional exchanges. Using the rewrite rules below, given by R. W. Floyd and D. E. Knuth [6], we can always rearrange a network to get rid of both misoriented comparators and unconditional exchanges. Thus we define the size of a sorting network to be the number of its comparators and don’t count any unconditional exchanges.

Nevertheless the additional freedom to rearrange channels as we see fit, provided by unconditional exchanges, can help when we analyze sorting networks.
Where are sorting networks used?
Before we dive deeper into the analysis and construction of sorting networks, I want to mention where they are useful.
The big advantage of sorting networks is that they can be implemented without any data-dependent control flow. A single comparator can usually implemented without branching by using conditional moves or some bit-twiddling to emulate those. Using such comparators, a single sorting network is just a linear branch-free sequence of instructions. A program like this is sometimes also called a straight-line program. This on its own is already useful for modern CPUs, where unpredictable branches come with a heavy performance penalty. But it also allows sorting multiple sequences at the same time using SIMD instructions where each SIMD lane is used to sort one sequence. It also maps very well to the programming model of GPUs.
Another useful property of sorting networks is that they can be implemented as a circuit. We get this circuit either from the data-flow graph of the straight line program or alternatively by interpreting our sorting network diagrams as circuits with comparators as gates. In general there are multiple sorting networks that map to the same circuit. For example, applying the rewrite rules above to a sorting network does not change its corresponding circuit.
Such a circuit can be implemented using digital logic in hardware. In fact, early “electronic data processing” was the first use of sorting networks: P. N. Armstrong, R. J. Nelson & D. J. O’Connor were the first to look into this around 19541. Their observations are described in the US patent 3,029,413 “Sorting System with -Line Sorting Switch”, filed in 1957.
Personally, I became interested in sorting networks as they can be used to encode cardinality constraints when using SAT solvers [5].
Identifying sorting networks
If I show you a sequence of comparators or a diagram and claim that they represent a sorting network, how do you verify or refute this? A sequence of comparators, without the requirement of producing a sorted output, is called a comparator network, so the question is how do we identify the sorting networks among all comparator networks.
One method is to apply brute force and try all possible inputs. For comparison sorting, only the relative order of the elements matters. This allows us to assume, without loss of generality, that our input sequence has values that are integers in the range for a network with channels. This leaves us with input sequences to try. For this is already more than , so this will work only for a very small number of channels. There are several arguments you can make2 to show that you only need to test permutations of , which reduces this number to . This is still growing extremely fast and for we would need to try more than input sequences.
We can do a lot better using the zero-one principle [9]. This is based on the fact that computing the minimum and maximum commutes with the application of a fixed monotone3 function, i.e. and when is monotone. Since a comparator computes the minimum and maximum, this means we can push or pull the application of fixed monotone function through all of a comparator network. Now assume that we have a network with an input sequence that is not sorted by our network:
![Diagram tracing the sequence 4, 1, 3, 2 to the sorting network [1,3][2,4][1,2][3,4] resulting in the non-sorted sequence 1, 3, 2, 4](diagram-not-sorted.svg)
We can find a pair of out-of-order output elements, here the second and third, and then define a monotone threshold-function that maps our values to the Booleans4 such that the the smaller out-of-order element is mapped to and the larger to . In our example we can use when and otherwise.
If we apply elementwise to the output sequence , we get and in general the sequence will remain unsorted.
As the function is monotone, we also know that applying it to the input before applying the comparator network will result in the same final unsorted output sequence:

This means that for every counter-example that shows that a comparator network is not a sorting network, there is at least one corresponding counter-example that uses a Boolean input sequence. Therefore trying all Boolean input sequences, of which there are , is sufficient to verify a sorting network. Of course exponential growth is still a lot, but it is a significant improvement over trying all permutations, even for quite small values of . Being only concerned with Boolean sequences is also often convenient for both theoretical analysis of sorting networks as well as for practical implementations of algorithms that deal with sorting networks.
Can we do any better? It turns out [10] that verifying a sorting network is among the Co-NP complete problems, thus we do not know a significantly better way to verify them that works for all networks. In my experience, though, for networks with a large enough number of channels, most networks we encounter while looking for good sorting networks can be verified a lot faster than brute force using CDCL based SAT solvers or either BDDs or ZDDs. This is the case for many NP-complete problems, where often the hard problem instances are not the ones of practical interest. Nevertheless, for a small number of channels, the simplicity of brute forcing through inputs is hard to beat.
Constructing sorting networks in practice
While checking whether arbitrary comparator networks are sorting networks is not very efficient, there are several systematic ways to construct sorting networks. A very simple approach based on a variant of the bubble sort algorithm uses comparators. The idea here is that a sequence of comparators can be used to find the largest element and move it to the end, then comparators are used to move the second largest element to its final position and so on until we know that all elements are sorted:
![5-Channel sorting network implementing the bubble sort variant described above. It shows comparators [1,2][2,3][3,4][4,5] to move the largest element to channel 5, followed by [1,2][2,3][3,4] to move the second largest element to channel 4, followed by [1,2][2,3] and finally [1,2]](diagram-bubble.svg)
This was already described in the patent mentioned earlier:
“A more general rule might be stated whereby an -line sorting switch might be constructed from an -line sorting switch by utilizing two line sorting switches and cascading them in a manner that these switches might successively compare the record being fed serially by bit into the added input terminal with each of the outputs of the n-line sorting switch which are ordered with respect to precedence, such that if the record being fed into the new input terminal has the highest precedences of all the records which are being compared simultaneously, it will be directed to the output terminal with the highest precedence.”
and
“This concept may be expressed by the formula,
Number of two line sorting switches
where is the number of lines.”.
The authors of the patent also noted that it is possible to do better:
“The -line sorting switches constructed after the plan described above […] do not generally represent the minimum number of two line switches which might be utilized, particularly as the number of lines is increased. By the use of skill, it is possible to design economical n-line sorting switches using a reduced number of two line sorting Switches.”
and gave the following examples:
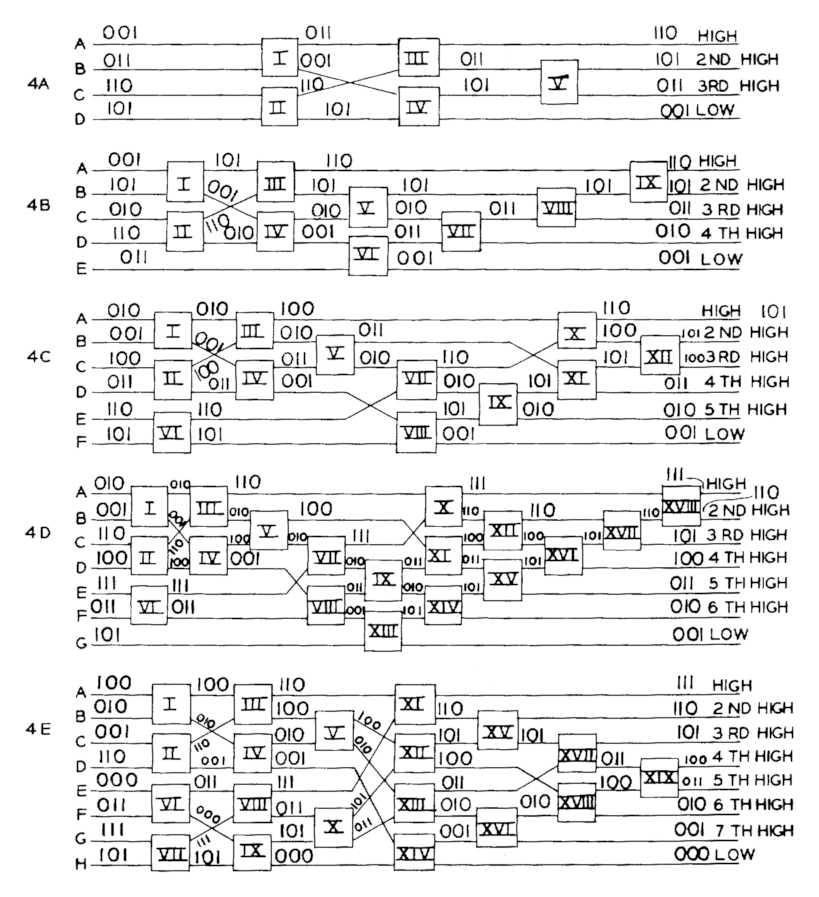
While Nelson & O’Connor’s patent does not describe a general method that improves upon this, R. C. Bose and R. J. Nelson did publish such a method in 1962 [3] which requires only many comparators.
Today the best ways to construct sorting networks in practice are the two merge sort variants by K. Batcher [2]: the bitonic merge sort and the odd-even merge sort. As a merge sorts they both work by dividing the sequence in halves, sorting each recursively and then using comparators to merge the two sorted halves into a single sorted sequence. The recursion terminates when only two elements are left to sort. Sorting two elements can be done using a single comparator. As the recursive structure only depends on the input size , it can be completely unrolled into a straight line program for a fixed and thus can be implemented as a sorting network.
A merge sort requires a logarithmic recursion depth, where the number of elements on each level, summed over all branches, stays constant. For general comparison sorts, where the order of operations is not fixed ahead of time, the merge can be performed in linear time, resulting in an asymptotically optimal overall run time for the merge sort.
It turns out that it is not possible to merge two sequences of equal length using a linear number of comparators using a fixed network.5 While Batcher’s two algorithms differ in how they perform this merge operation, they both implement it using a recursive divide and conquer approach.
How exactly they perform the merge operation as a comparator network is out of scope for this post, but my go to reference for this are H. W. Lang’s pages on the bitonic sort and on the odd-even mergesort.
For both, a merge takes comparators, resulting in an overall size of . This grows faster than the run time for the best algorithms for general comparison sorts, but only by an additional logarithmic factor. I’d say in most settings where sorting networks are required or advantageous, this second logarithmic factor is unlikely to be a showstopper.
Nevertheless, it turns out that the networks generated by both algorithms are not optimal in size. Better networks for small input sizes were found early on using systematic manual trial and error. Using those manually found networks, it is possible to improve the constant factor hiding in the big- of either the bitonic or the odd-even merge sort. To do so, we terminate the outer merge-sort recursion as soon as the input size falls below fixed input size threshold. At that point we sort the input using a fixed pre-computed network that is smaller than continuing the merge-sort would be. This motivates finding better sorting networks for small input sizes, even if we are only interested in sorting larger sequences.
It also raises the question what exactly the optimal sorting network size is, including whether the additional logarithmic factor is necessary.
Optimal sorting networks
This very question is known as the Bose–Nelson sorting problem, after R. C. Bose and R. J. Nelson who published the first analysis of this problem [3] and their -comparator construction.
For some time, before Batcher published his first algorithm in 1968 [2], it was even conjectured that is optimal. For many years no one managed to find networks with a better size complexity than Batcher’s , so it seemed like this might be the best one can do. Thus, I’m sure it was a big surprise when M. Ajtai, J. Komlós, and E. Szemerédi [1] published a construction for sorting networks of size in 1983. The networks they described are known as AKS sorting networks. Their size matches the lower bound for the asymptotic growth rate of general comparison sort run time. As this lower bound also applies to the special case of sorting network size, AKS networks have an optimal asymptotic size
So why didn’t I mention this in the previous section, when it clearly is better than Batcher’s networks? As always, big-s only tell part of the story. The optimal asymptotic growth rate does not help in practice if the hidden constant factors are too large. And large they are in the case of AKS sorting networks, or as Knuth puts it: “Batcher’s method is much better, unless exceeds the total memory capacity of all computers on earth!” [9]. This makes AKS networks a galactic algorithm.
There are newer constructions [8] that greatly improved the constant factor, but even for those, Batcher’s sorting networks will be smaller for any practical number of channels.
Nevertheless we do have many examples of practical sorting networks that are smaller, in absolute terms, than those produced using Batcher’s methods. We just don’t have an efficient systematic way of constructing those for arbitrary sizes. This makes it interesting to focus on the absolute sizes of sorting networks, not just their asymptotic growth.
Besides coming up with general methods to construct sorting networks of any size, we can also try to find good sorting networks for a fixed given number of channels . We already saw that answering whether a given comparator network is a sorting network is not an easy problem, so we shouldn’t expect this to be easy either.
For very small , systematic manual trial and error works well enough, but starting at the best known networks were found using heuristic computer searches, often based on genetic algorithms. Knuth’s “The Art of Computer Programming” vol. 3. lists the best known networks for . These networks have been known for a while. Beyond that, B. Dobbelaere maintains a list which includes recent updates for .
Currently the best known sizes are:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
| size | 0 | 1 | 3 | 5 | 9 | 12 | 16 | 19 | 25 | 29 | 35 | 39 | 45 | 51 | 56 | 60 |
While using systematic trial and error or heuristic searches is quite effective at discovering good sorting networks, you would not know whether the best sorting network found so far is of optimal size or whether you can still find a shorter one.
Proving optimality
To prove that a sorting network has optimal size, we have to exclude the possibility of any smaller network. The brute-force approach would be to enumerate all smaller sorting networks, but this becomes infeasible very quickly. Thus we need to find ways to exclude many smaller sorting networks at once.
One way to do this is the information theoretic bound for comparison sorts. Despite the name, there is no need to invoke information theory, elementary combinatorics is sufficient to state it: There are permutations of distinct6 elements, and a comparison based sorting algorithm necessarily needs to distinguish all of them. Each comparison has two outcomes so there are possible outcomes for comparisons. We can only distinguish all input permutations, if we have more possible outcomes, so we need to have or equivalently . This is also how we can derive the lower bound for comparison sorts, as .
With this we get that sorting networks with or channels have at least or comparators respectively. Looking at the table of the smallest known networks, we see that the networks for and inputs must be optimal. Starting with channels, though there is a gap between the information theoretic bound and the best known networks, so we need to find a better way to show that smaller networks don’t exist.
Floyd and Knuth [6] did a manual case analysis for 5 channels using the zero-one principle, showing that the smallest network has 9 comparators. For 7 channels they used a computer program to handle the much larger number of candidates that needed to be checked. The result was that 16 comparators are required. This took 20 hours on a CDC G-12 computer in 1966. To solve the problem for 6 and 8 channels, they proved that starting with 5 channels, adding another channel requires at least an additional 3 comparators for the smallest sorting network. Knowing the optimal sizes for 5 and 7 channels, this gives 12 and 19 comparators as lower bounds on 6 and 8 channels respectively. These match the sizes of networks that were already known at the time and which thus are also optimal.
The following sorting networks, taken from Dobbelaere’s list, are examples of such optimal sized networks:




Around the same time D. C. Van Voorhis found an even better way [11] to go from a lower bound for channels to a lower bound for channels. Writing for the size of the smallest sorting network with channels, he showed that . Iterating this gives a lower bound for that also grows on the order of , the same as with the information theoretic bound. In absolute terms though, it does improve upon the information theoretic bound and has the advantage that it carries forward any improvement for bounding a specific by other means. Still, Van Voorhis’s lower bound only gives us , while the best known network has a size of 25.
It took almost 50 years for any further improvement to be made. In 2014 M. Codish, L. Cruz-Filipe, M. Frank, P. Schneider-Kamp managed to compute the minimal number of required comparators for sorting 9 values [4]. They used a computer search that incrementally builds a sorting network from front to back. For this they start with an empty comparator network as initial candidate prefix. In every iteration, a new set of candidates is generated from the previous set. The comparator networks generated in that step are obtained from the previous networks by extending every candidate of the previous step with every possible comparator. Note that all candidates produced in the same step have the same number of comparators, which also means that the first sorting network obtained in any step will be of minimal size.

This alone would lead to a very rapidly exploding set of candidates, so interleaved between these network generating steps, they introduce a pruning step that tries to eliminate as many candidates as possible while ensuring that there is at least one remaining candidate which can be extended to an optimal size sorting network.
To do this pruning, they use the zero-one principle. For each candidate network , they apply all Boolean input sequences and collect the set of output sequences .
Now if any two candidate networks and that were produced in a generate step have sets of output sequences where one is a subset of the other, i.e. , this relationship remains when both candidates are extended in the same way. In other words, for any suffix of comparators used to extend them, we still have . This is the case, as we can compute from , by applying to each sequence of and collecting the resulting sequences. Hence removing a sequence from cannot introduce a new sequence in .
Now if there is a way to extend to an optimal size sorting network , i.e. contains only sorted sequences, then will also be a sorting network of the same size because also contains only sorted sequences. This means there is no need to keep around as a candidate. By comparing the sets of outputs for each pair of candidates, the set of all candidates can be pruned to the set of candidates where each has a set of outputs that is minimal with respect to inclusion. If multiple candidates have the exactly the same set of output sequences, we can pick the one to keep arbitrarily.
We can see that even for only 3 channels, this already removes a lot of candidates in the second step:
![Same tree as before, but showing the possible outputs of each comparator network and the subset relationship of those sets for the second layer. Every set of outputs on that layer is a superset of or equal to the set of outputs of either [1,2][1,3] or [1,2][2,3], so all other size 2 networks can be pruned.](subset.svg)
This is not quite yet the full approach used by Codish et al. Instead of using set inclusion to compare output sets, they define a relation called subsumption. Remember that above, where we introduced sorting networks, we noted that unconditional exchanges do not count towards the networks size as we can always rearrange the network to eliminate them. Therefore for two candidate sorting network prefixes and for which there is a sequence of unconditional exchanges such that , the same extension argument can be made to show that for any suffix . In this case subsumes , and again there is no need to keep the candidate around, as for any sorting network , the network will also be a sorting network of the same size. Note that any sequence of unconditional exchanges corresponds to a permutation and vice versa, so effectively this exploits symmetry under permutation.
Using subsumption prunes a lot more candidates than just set inclusion. Below you can see all non-pruned candidates for a generate-and-prune run for four input channels. If we were using only set inclusion, the fourth layer would have 13 and not 4 candidates, and the difference gets even larger when we increase the number of channels.

With this generate-and-prune approach and an implementation that uses smart way of finding subsuming pairs of candidates, Codish et al. managed to compute . This computation took a significant amount of time. They used a 144 core cluster on which the computation took 12 days.7
With 9 channels solved, the question is: does this help for even more channels? Applying Van Voorhis’s bound for 10 channels, gives . This matches the already known sorting network found in 1969 by A. Waksman [9], so their computation for also produced at the same time.
Directly computing using this generate-and-prune approach would be much more costly in both time and memory or storage requirements. I think that this is likely not feasible. Adding another channel to compute certainly remains out of reach for this approach.
Not finding better sorting networks
At first I didn’t set out to prove optimality of any sorting networks. Instead I wanted to experiment with algorithms to find better sorting networks. My hope was that I might be able to find a smaller sorting network for one of the input sizes where the gap between the best known size and the best proven lower bound is sufficiently large that better networks are likely to exist.
While reviewing the literature to learn about existing results about sorting networks, I then came across the results of Codish et al. Their approach to pruning the search space seemed relevant to what I was trying at that point, even while I was still trying to find smaller sorting networks at that point.
I had some rough ideas on how I could speed up their algorithm: I would keep the same overall approach I outlined above, but I would replace the data structures and algorithms used to implement the individual steps. While working out the details I also came across a paper by C. Frăsinaru and M. Răschip who already did some work in that direction, getting significant speedups [7]. My ideas went further, but I could build on their improvements.
In the end my implementation of the generate-and-prune method is able to replicate the computation of in under an hour on my desktop workstation. This is the same computation that initially took 12 days on a cluster. I finished this in the summer of 2019 and published my source code on GitHub. From my experiments while implementing this, it was pretty clear to me that this method alone, even with all those improvements, would not scale to the next input size for which the problem was open.
During all this I also came across Van Voorhis’s bound, as it was used to answer the problem for based on the computation of , and was impressed by how effective it is given that it alone takes care of half of the known minimal sorting network sizes. But it wasn’t used for any of the computer searches for the other known minimal sizes. This made me try to find a way to somehow integrate it into a computer search, but my initial attempts did not work out, so at first I focused on improving the generate-and-prune method.
After I finished my implementation of that, I decided to revisit my earlier attempts at integrating Van Voorhis’s bound into a computer search. This time I was more successful and ultimately, exploring this led me to prove the optimality of the 11 and 12-channel sorting networks found by G. Shapiro and M. W. Green, solving a long standing open problem.
I also extended my method to produce a proof certificate that can be checked with a formally verified program, to make really sure that my approach is sound. After I succeeded with that, I published my source code and formal proof on GitHub and announced my result in December 2019. I still had to write up all the details and a proof that my method works in general, which I did during the following year. The resulting paper is available on arXiv.
More details
For the next part of this series I plan to describe what I came up with and how it works, essentially summarizing the key parts of my paper. If you don’t want to miss it, you can subscribe to the RSS feed or follow me on Mastodon.
References
According to Knuth’s overview of the problem’s history [9].↩︎
For example by using that a comparator is a continuous function on the real numbers, as is any composition of them. For any input sequence that is not sorted by the comparator network, this allows you to slightly perturb the inputs to avoid equal elements, while still keeping the output unsorted. Then you can renumber the input values from , keeping their relative order, producing a permutation of that is also not sorted.↩︎
In the order theory meaning, so for a total order, monotone means weakly increasing and antitone means weakly decreasing.↩︎
Using and instead of false and true as Boolean values to emphasize their order.↩︎
The case of inputs where values appear multiple times can be reduced to the case where all values are distinct, for example by using the lexicographic order of element value and initial element position. In any case, for a lower bound we are also allowed to ignore some possible inputs.↩︎
They also performed a computation using a hybrid approach that combines generate-and-prune with a method based on SAT solving, which cut down the total time to around 8 days.↩︎